Pipeshift Partners with Armada to Bring Open-Source Inference to Bridge Marketplace
Armada Bridge customers can now access Pipeshift for production open-source LLM inference

Arko C
CEO
Published
Topic
Partnership

Pipeshift is excited to partner with Armada.ai as part of the launch of Bridge Marketplace, Armada’s new ecosystem for validated AI infrastructure software.
Through the marketplace, Armada Bridge customers can access Pipeshift for production open-source LLM inference.
Pipeshift brings MAGIC, its model optimization framework for serving workloads across latency, throughput, and cost constraints.
The partnership gives Bridge customers a direct way to run optimized model endpoints on secure compute infrastructure provided through Armada.
Teams can use Pipeshift to turn open-source LLMs into inference services for internal applications, customer-facing products, and regulated AI workloads.
Once the GPU infrastructure is available, the serving path still has to be built
Armada Bridge gives businesses a way to access secure compute infrastructure for AI workloads.
That includes the operational layer around multi-tenant access, scheduling, orchestration, billing, infrastructure services, and platform services.
Production AI still needs model endpoints that hold latency, throughput, and cost behavior under real demand.
Pipeshift works on that inference path, optimizing runtime decisions such as:
how the model is served
how requests move through the runtime
how the endpoint balances latency, throughput, and cost
MAGIC tunes the serving path around each workload
MAGIC is Pipeshift’s model optimization framework for production inference.
After a team selects a model and compute target, the serving setup still has to match the workload. Chat traffic, batch jobs, and long-context pipelines each need different runtime behavior.
Different AI workloads put pressure on different parts of the serving path:
Chat and agent endpoints: prioritize first-token latency, streaming behavior, and queue control during traffic spikes
Coding workloads: need stable decode performance across longer responses and concurrent users
Long-context and RAG workloads: put heavier pressure on prefill, memory movement, and cache reuse
Batch inference jobs: push for higher GPU utilization while keeping them away from latency-sensitive endpoints
Structured-output endpoints: need reliable formatting and tool-call behavior without adding heavy serving overhead
The diagram below shows the flow from Armada Bridge compute infrastructure to a workload-specific inference endpoint.
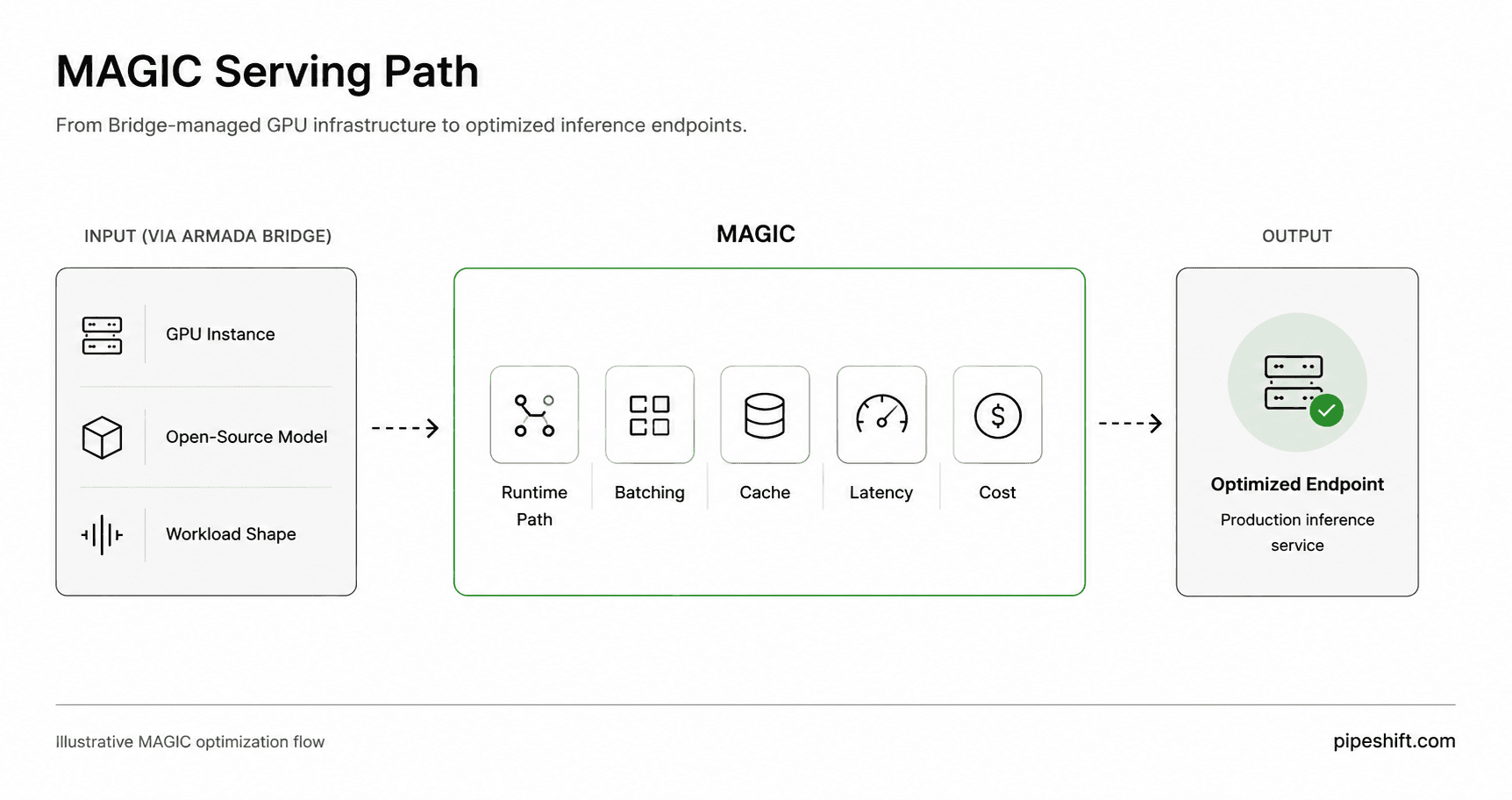
MAGIC gives each workload a serving path matched to its runtime pressure. A latency-sensitive endpoint, a long-context pipeline, and a batch job each need different runtime assumptions.
Bridge customers can use Pipeshift to run open-source models as purpose-built inference endpoints on compute infrastructure provided through Armada.
AI teams should be able to request model endpoints directly
For Bridge customers, Pipeshift makes secure compute infrastructure easier to use for production model serving.
AI demand rarely arrives as one clean workload.
A coding assistant, internal RAG system, support agent, and batch summarization job can run inside the same business with different serving requirements.
Those requests may involve Qwen, Llama, DeepSeek, Mistral, Gemma, or another open-source model the team wants to run.
Infrastructure teams need a repeatable serving layer for new models, workloads, and application requirements.
And, the operators need a repeatable serving layer for new models, workloads, and tenant requirements.
Pipeshift helps standardize that layer across open-source inference deployments.
A new endpoint can start from a known serving pattern, then get tuned for the model, workload, and capacity target.
We’re excited to support Armada customers building production AI infrastructure
Pipeshift is glad to support the launch of Armada Bridge Marketplace.
Armada Bridge customers can find Pipeshift in the marketplace to explore production open-source LLM inference on secure compute infrastructure provided through Armada.
Teams that want to discuss a specific model, workload, or deployment target can also reach out to Pipeshift directly.
