Pipeshift and Neysa Partner to Bring Real-Time Open-Source AI Inference to India
Indian AI teams can now run production open-source LLM inference inside India

Arko C
CEO
Published
Topic
Partnership

Pipeshift is partnering with Neysa to help Indian companies run real-time open-source AI inference inside India.
Closed APIs helped many AI teams ship their first products quickly. But as usage grows, teams start looking for more control over model choice, cost, latency, and where inference runs.
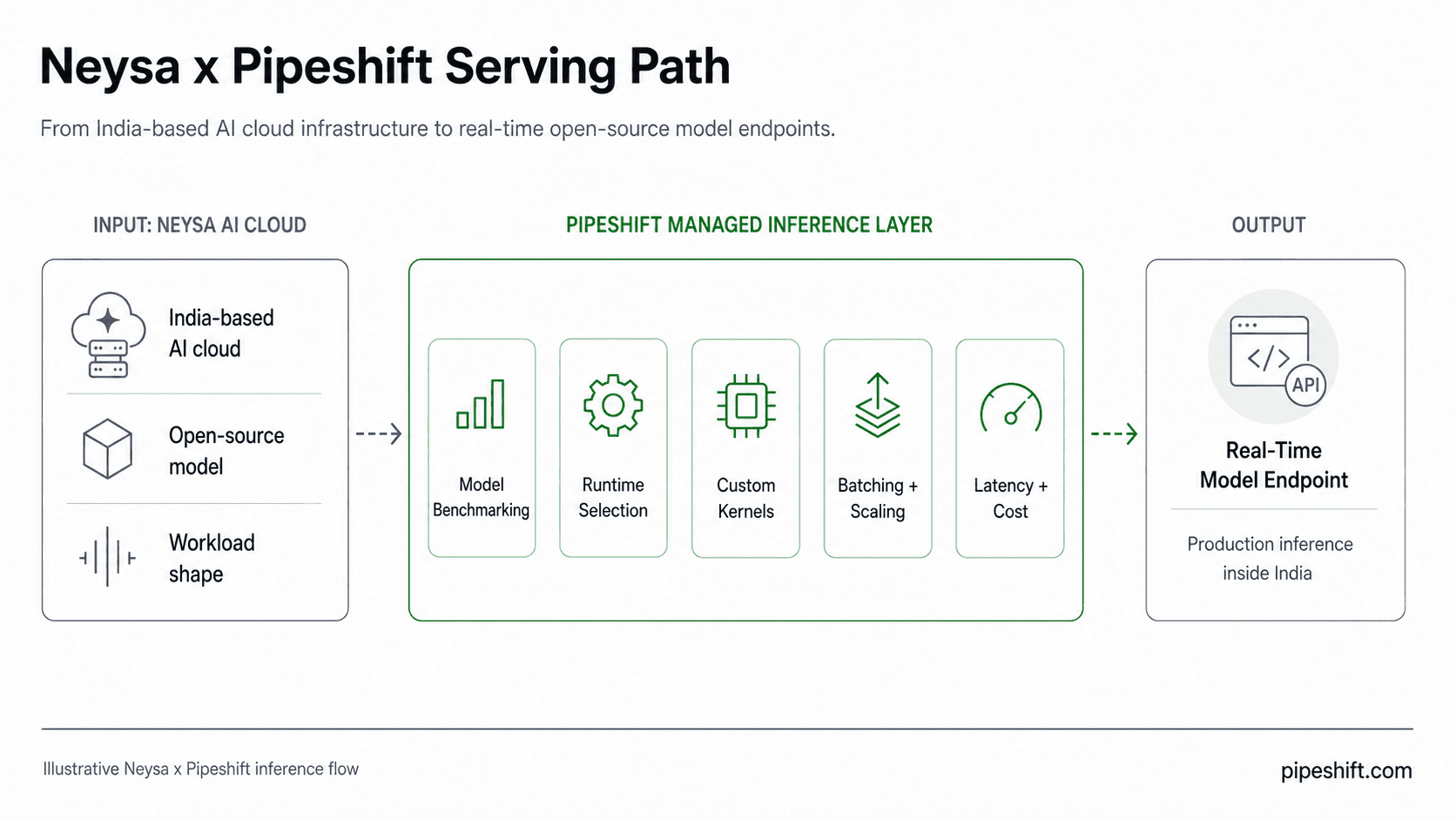
Neysa provides the India-based AI cloud infrastructure layer for production AI workloads. Pipeshift brings the managed inference layer that turns open-source models into real-time endpoints tuned for latency, throughput, and cost.
Together, Neysa and Pipeshift give Indian AI teams a path to run production open-source LLM inference inside India without building the full GPU serving stack themselves.
Closed APIs make it easy to start, but harder to scale
A closed API is a good default when the product is still being tested. The problem starts when inference volume becomes part of the business model.
Scale changes the calculation. Token pricing starts as a usage-based convenience, then turns into a margin problem. Provider-side model changes, rate limits, and pricing changes also stay outside the team’s control.
For an Indian company, the region question adds another constraint. The team may want the simplicity of an API, but also need more control over where inference runs, how capacity is managed, and how predictable the serving path is under real traffic.
Open-source models give teams a more controllable path. Model weights alone do not create a production endpoint. Production inference still needs accelerator capacity, runtime tuning, scaling policy, monitoring, and endpoint operations.
Neysa provides the India-based AI cloud layer
Neysa is India’s AI Acceleration Cloud, built for companies running AI workloads in production.
For the Neysa and Pipeshift partnership, Neysa provides the AI-native cloud platform inside India.
Customers get access to the infrastructure layer for production inference, along with the security, compliance, and data-residency posture Indian enterprises need.
Local inference changes the serving path. When requests move through regions or cloud paths built around other markets, every call pays a latency tax before the model starts useful work. Real-time products feel that delay immediately.
Running inference inside India gives teams a shorter path between users, infrastructure, and enterprise requirements.
Neysa provides the local AI cloud layer. Pipeshift turns that local infrastructure into real-time open-source model endpoints.
Pipeshift turns infrastructure into real-time model endpoints
Local infrastructure solves where inference runs. Production inference still depends on the serving path around the model.
For customers, the useful output is not a GPU cluster. The useful output is an endpoint that can meet the workload’s latency, throughput, and cost targets under real traffic.
Pipeshift builds that serving layer on Neysa. The team benchmarks open-source models against the customer’s workload, selects the inference engine, tunes the runtime path, and configures the endpoint around the required SLA.
That work can include vLLM or SGLang selection, custom CUDA kernels, parallelization strategy, batching behavior, autoscaling, failover, and model swaps as newer open-source releases become available.
Customers still get the managed API experience. Pipeshift provides an OpenAI-compatible endpoint that can plug into the existing application stack without asking the customer’s team to manage the full serving path.
Open-source models need a managed serving path
A customer starts with the workload already running today: the current model, eval set, latency target, traffic pattern, and monthly spend range.
Pipeshift and Neysa use those inputs to design the inference setup. The work starts with model testing against the customer’s evals, then moves into serving decisions:
vLLM or SGLang
custom CUDA kernels
parallelization strategy
batching behavior
capacity planning
The result is a dedicated endpoint on Neysa’s India-based cloud infrastructure. The endpoint is OpenAI-compatible, so the customer can connect through the same API pattern already used in the application stack.
Instead of | Customers get |
Per-token API pricing that grows with every request | A monthly spend pool tied to the workload |
Fixed GPU ownership before traffic is predictable | Reserved baseline capacity plus on-demand scale-up |
Rebuilding serving logic for every new model | A managed endpoint that can be re-benchmarked and updated |
Picking a model from a public leaderboard | Model and runtime testing against the customer’s evals |
As newer open-source models, runtimes, and accelerators become available, Pipeshift can re-benchmark the endpoint and update the serving path without forcing the customer to rebuild the stack.
What production real-time inference looks like
Production inference is where the serving path gets tested: first-token latency, streaming behavior, queue pressure, cache reuse, and cost under load.
A production endpoint has to match the workload it serves:
Voice agents need fast first-token latency and stable streaming because every pause becomes part of the conversation.
Support copilots need predictable response time during peak hours.
Long-context RAG workflows need enough memory and cache behavior to avoid slow prefill on every request.
Batch workflows need throughput without crowding the endpoints serving users in real time.
Let’s see that with an example.
Nurix AI runs voice agents in production. The team needed sub-second LLM latency, but its previous setup in India could not hold the response profile it needed.
With real-time inference from Neysa and Pipeshift, Nurix cut TTFT by 3x versus its previous setup in India.
“We needed sub-second LLM latency for voice agents in production, and real-time inference from Neysa and Pipeshift cut our TTFT 3x versus our prior setup in India. Their team’s support and quick resolution time has helped make seamless rollouts to production.”
Pushkar Patel, Nurix AI
For teams building real-time products, that is the point of the partnership. Neysa keeps the infrastructure layer inside India. Pipeshift runs the managed inference layer that helps the endpoint hold latency when users are actually interacting with the product.
Supporting production AI in India
Pipeshift is glad to partner with Neysa to support Indian companies moving open-source AI into production.
Neysa brings the India-based AI cloud layer. Pipeshift brings the managed inference layer for real-time model endpoints. Together, the partnership gives teams a way to run production inference inside India without choosing between closed APIs and building the full serving stack internally.
Teams evaluating real-time inference on Neysa can bring their current workload, eval set, latency target, traffic pattern, and monthly spend range. Pipeshift and Neysa can benchmark the model, serving engine, kernel path, and capacity plan before the endpoint moves into production.
For Indian companies building voice agents, copilots, support workflows, and other latency-sensitive AI products, the path is direct: test the workload, stand up the endpoint, and run open-source inference closer to users and enterprise requirements.
