The Black Box Trap: How Rented AI Kills Margins at Scale
What rented inference costs you and how to avoid it.

Aryan Kargwal
PhD Candidate at PolyMTL
Published
Topic
Inference Infrastructure

Every time your AI product calls an external API, you're paying a toll you didn't negotiate, on infrastructure someone else owns, to a provider who can reprice you overnight. That specific lease seems like you can never escape it.
The real problem is opacity. When your intelligence layer lives inside someone else's infrastructure, you lose the ability to understand what actually makes your product work. Which inputs actually drive the best outputs. Which calls are burning your budget. Which parts of your pipeline are carrying the weight and which are dead cost.
You are operating a business on an engine you have never seen. That engine has a name: black box AI.
In this article I will walk you through the real challenges that come with relying on black box inference providers when you are trying to scale and actually own the thing you are selling.
What Is Black Box AI?
Black box AI is exactly what it sounds like. You send in a request, something happens inside infrastructure you have never seen, and you get an output back. For a while, that feels fine. The outputs are good, the integration is clean, and the whole thing moves fast.
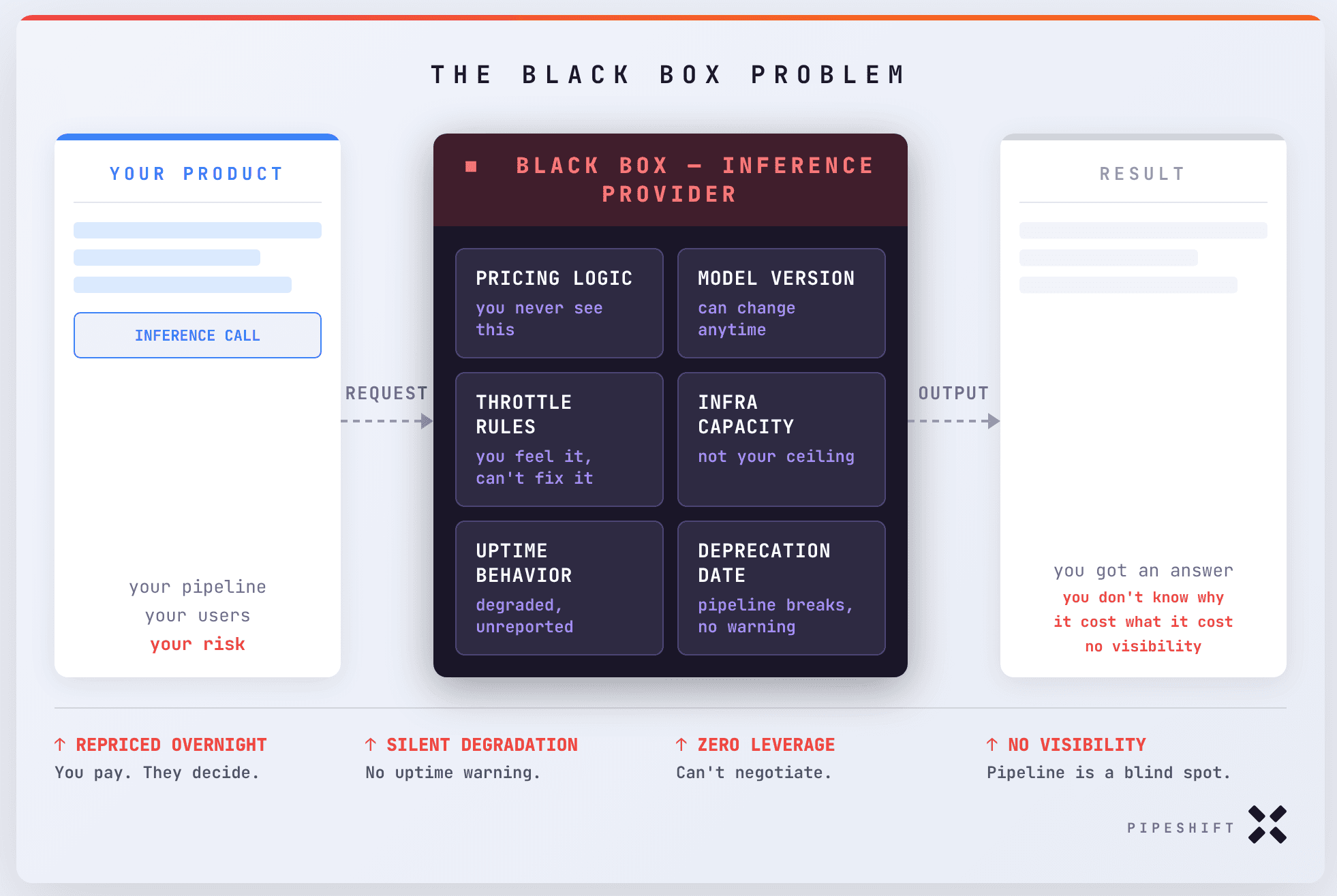
But here is what that arrangement actually looks like under the hood. Anthropic is running Claude on their own infrastructure. OpenAI is running GPT on theirs. These are massive, shared, multi-tenant environments. They throttle. They go down. They degrade quietly (sometimes not even reported on the uptime pages) under load. And when they do, you feel it, but you cannot see why.
Now that is already a real problem when you are building on a generalized model that does a bit of everything. But the moment you go specialized, it becomes a structural one. Say your product is running a vision layer on Qwen VL, a writing agent on GPTOSS, and a function calling pipeline on Kimi.
You are now dependent on three separate black boxes, each with their own uptime guarantees, their own throttling behavior, their own pricing logic, and their own deployment decisions that you have zero say in. Your product's performance is a function of all three, and you have visibility into none of them.
The Vertical AI Imperative
If you are building a school copilot or a roleplay product, renting from a generalized provider is the right call. GPT-4o and models like it are built for exactly that surface area. Wide, conversational, good enough across a huge range of inputs. Character AI is a perfect example of a product where the generalized model is not a compromise, it is the product.
But the moment your pipeline gets specific, that same arrangement starts working against you. The best move is to stop thinking in terms of one model altogether. Go completely purpose-built, pick the best model for each job, and run the whole thing inside the infrastructure you actually own.
A 1 billion parameter model using test-time scaling outperformed a 405 billion parameter model on complex math benchmarks, and a Qwen 2.5 model with just 500 million parameters beat GPT-4o with the right inference strategy. Smaller models can now outperform ones 100 to 1000 times their size.
You no longer need to rent a massive generalized model to get great performance. Run something lean and purpose-built, give it the compute it needs at inference time, and you beat the black box on both performance and cost.
From Black Box to Your Box
So you've accepted the premise. Smaller models, right inference strategy, better performance at lower cost. But "right inference strategy" is doing a lot of heavy lifting in that sentence. What does it actually mean in practice?
The problem is that most real pipelines need multiple inference engines working together. Your vision layer has different requirements than your writing agent. Your function calling pipeline is different again. Managing that across backends manually is an engineering sink that never stops draining.
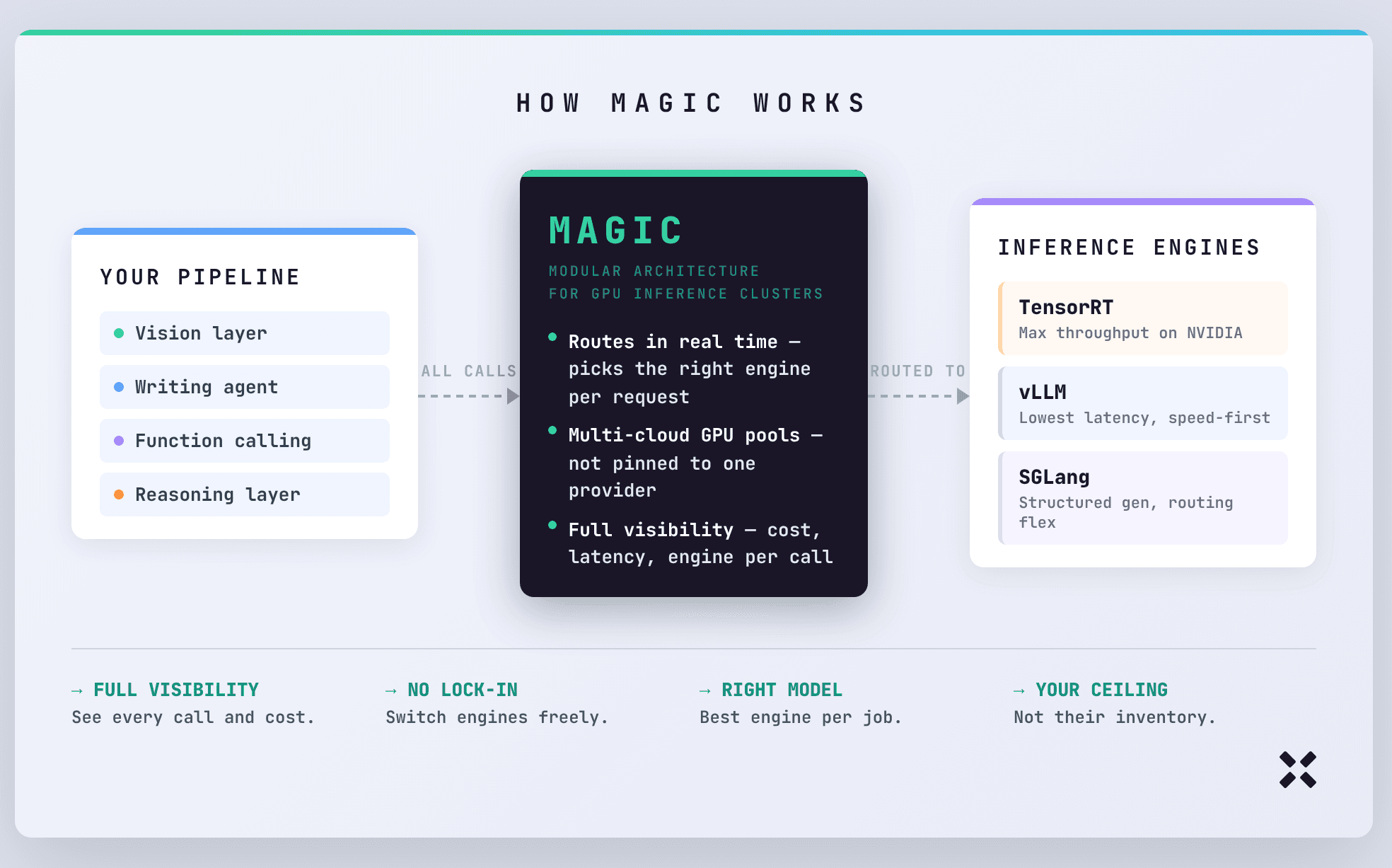
That's the problem MAGIC is built to solve.
MAGIC, Pipeshift's Modular Architecture for GPU Inference Clusters, is the layer that sits between your pipeline and your inference backends. It decides in real time which engine handles which request, pulls from GPU pools across multiple clouds rather than pinning you to one provider's capacity, and routes everything automatically so your team isn't manually managing what runs where.
If you're on stable NVIDIA hardware and want maximum throughput, TensorRT is built for that environment and when the conditions are right, nothing touches it. If speed is the priority, vLLM is where serious teams go. SGLang sits somewhere between the two, better for workloads that need routing flexibility or structured generation and don't fit neatly into either camp.
By giving a way to bridge the fundamental differences between these engines through a dynamic architecture, the ceiling of your infrastructure stops being someone else's inventory limit and starts being yours to define.
Which brings us to the actual decision.
Staying in the Box or Getting Out
Most founders think about AI ownership in terms of the model. Which model they're using, whether it's open source, whether they can fine-tune it. But model ownership without infrastructure ownership is just a different kind of dependency. You can own the weights and still have no idea what your inference is actually costing you, why it spiked last Tuesday, or what breaks when you scale to ten times the traffic.
The teams that feel this most aren't the ones who just started building. They're the ones who are eighteen months in, have a product that works, and are now realising that every optimization they make is happening on top of a foundation they don't control. And although a migration to a more efficient system seems daunting, Pipeshift is built for exactly such usecases.
Pipeshift is built for the teams that have hit that wall or can see it coming. Not to rip out everything you've built, but to give you an actual foundation, one where you can see what's happening, route workloads to the right backends, and stop paying the black box tax on every inference call.
The box was always optional.
