Model Selection for Inference Efficiency
Why Performance Trumps Intelligence at Scale

Aryan Kargwal
PhD Candidate at PolyMTL
Published
Topic
Model Deployment

Airbnb CEO Brian Chesky on new product updates, integrating AI and state of AI tech race
Earlier this week, in a CNBC interview, Airbnb CEO Brian Chesky explained that the company hasn’t integrated ChatGPT into its app because OpenAI’s “connective tools aren’t quite ready.”
What stood out was what he said next: Airbnb has been using Alibaba’s Qwen, describing it as “very good… fast and cheap.”
That brief remark signals how large companies are starting to think about AI deployment. Many teams that once reached straight for GPT-4 or Claude are now choosing inference-efficient models — designed to serve faster, cost less to run, and give engineers more operational control.
What did the Airbnb CEO say?
Airbnb CEO Brian Chesky explained that the company hasn’t yet integrated ChatGPT into its platform because OpenAI’s “connective tools aren’t quite ready.” He went on to add that Airbnb has been relying heavily on Alibaba’s Qwen, calling it “very good — fast and cheap.”
Taken at face value, it appears to be a straightforward technical update. However, in context, it reveals how large consumer platforms now approach AI integration. Chesky wasn’t questioning GPT’s intelligence; in fact, he told Bloomberg recently that it is among the 13 or so models that they currently use in their stack.
Chesky, in the interview, is pointing out that connecting large, closed models into live systems still creates operational friction. Airbnb’s scale demands predictable uptime, low latency, and stable serving costs across millions of transactions, and most general-purpose APIs aren’t built for that yet.
In that setting, a few hundred milliseconds of delay per request is a cost and throughput problem. Every millisecond compounds across millions of interactions. For Airbnb, the model that wins is the one that responds first and stays stable when demand peaks.
Chesky’s comment points to a larger truth: enterprise AI performance now depends less on frontier capability and more on the infrastructure that can keep it online.
The Economics of Inference Decide Everything
When the competition is only about model capability, you compare benchmarks — accuracy, reasoning depth, tool calling, and multimodal performance. But when you move to production, the economics shift to two numbers that actually decide everything: time to first token (TTFT) and cost per token.
Time to First Token
For a company like Airbnb, its AI system handles real users in real time. When a guest sends a message or raises an issue, the first few seconds of that interaction decide whether they stay engaged or leave frustrated. The model doesn’t need to compose an essay or draft a JSON call — it just needs to reply quickly enough to keep the conversation alive.
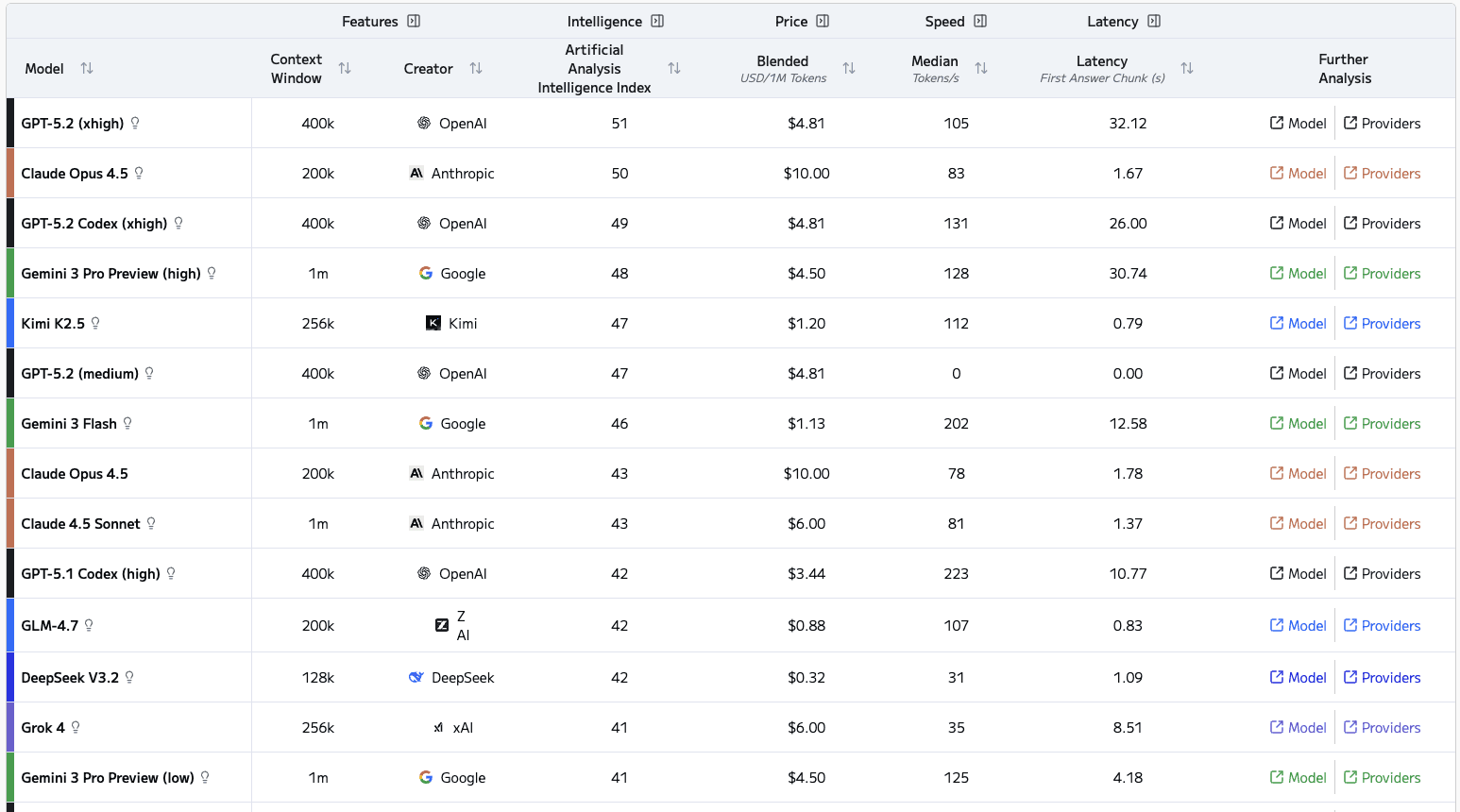
When you check the latest latency data (Source: Artificial Analysis), the difference is striking.
This delay comes from how GPT-class models initialize, multiple safety filters, reasoning pre-passes, and adaptive batching add seconds before streaming. Qwen and GPT-oss-120B start almost instantly, using lighter stacks and simpler decoding paths for steady real-time, quick use.
Cost Per Token
Once latency is under control, cost per token becomes the next bottleneck. It measures how much each generated unit of text costs to produce under real production traffic.
High-capacity models like GPT-5 process longer contexts and generate more verbose completions. Each step adds reasoning overhead and inflates token usage, turning simple interactions into multi-loop tasks which honestly could have been avoided. So signaled by the popular demand to bring back GPT-4
That overhead translates into real spend. GPT-5 sits near $3.44 per million tokens, while Qwen3-235B averages $1.80. Even GPT-oss-120B stays around $1.60 when deployed locally.
At scale, that gap compounds. Millions of short support chats can push inference bills up by thousands of dollars each day if the model uses longer completions than required for the task.
Cheaper models paired with strong retrievers and lightweight memory modules avoid that waste. They keep responses short, grounded, and consistent, exactly what platforms like Airbnb need for high-volume, low-variance workloads.
Shared Endpoints Break Under Traffic
The high cost per token for models like GPT-5 or Claude comes from where they live shared, multi-tenant clusters. Each request competes for limited capacity inside OpenAI or Anthropic’s global systems.
That setup adds invisible overhead. Queues build up, redundancy layers trigger, and routing safeguards slow the first output. Every request travels through extra hops and batching logic before a reply begins.
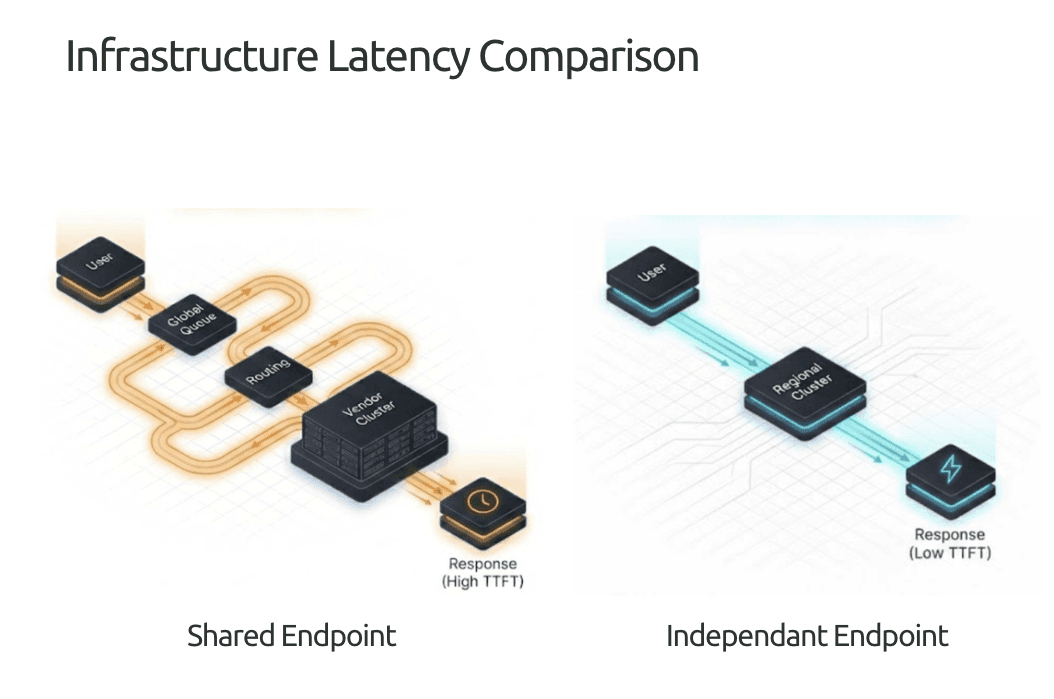
The low-latency results seen with Qwen or DeepSeek come from independent deployments such as Pipeshift, vLLM clusters, or custom Triton setups running open weights on private or regional GPUs. These run open weights on private or regional GPUs, far from the congestion of public endpoints.
Running close to the user removes most of the overhead. There is less global traffic, fewer safety layers, and minimal dynamic routing. The model isn’t inherently cheaper the efficiency comes from its deployment path.
That’s why many production teams move to dedicated inference. They value consistent latency and predictable cost over benchmark superiority.
How Inference-Efficient AI is Built
Airbnb’s CEO wasn’t comparing raw intelligence. He was describing what every production team eventually realizes — inference is an infrastructure problem.
Let’s look at what defines that stability in practice the key priorities your inference provider must meet, and how each one directly shapes cost, latency, and reliability at scale.
What to look for in your inference provider?
Deterministic latency: Providers should share p95 and p99 numbers. Mean latency hides load spikes that directly affect user experience.
Warm pools and batching: Efficient systems reuse GPU memory between requests and batch inputs by token length. Consistent memory reuse prevents startup delays.
Regional placement: Confirm where inference actually runs. Strong providers keep execution close to the user and maintain KV-caches within the same region.
Framework routing: Each workload type benefits from a specific engine — vLLM, Triton, or LMDeploy. The best setups route intelligently instead of using a single framework.
Custom kernels and cache control: Providers that develop their own kernels, such as MAGIC’s GPU bin-packing, maintain high utilization and predictable throughput.
Observability hooks: Teams need logs and metrics that track cache hits, TTFT, and cost per token. Reliable observability ensures performance trends stay visible and manageable.
Inference Options at a Glance
Once you know what to evaluate, the next question is who actually delivers on those metrics.
Here’s a snapshot of the top inference options today:
Platform | Framework Layer | Cache & Batching | Regional Placement | Observability | Notes |
Pipeshift (MAGIC) | Adaptive routing (vLLM, Triton, TRT-LLM) | Dynamic + deterministic batching | Multi-region, latency-aware | Full metrics and replay logs | Modular GPU Inference Clusters (MAGIC) auto-balance load |
vLLM OSS | vLLM | Manual | Self-hosted | Depends on setup | Baseline open-source inference layer |
Anyscale Endpoints | vLLM + Ray Serve | Dynamic | US/EU regions | Partial | Good concurrency, weaker cache persistence |
SageMaker JumpStart | TGI/Triton | Managed autoscale | Region-selective | Partial | Strong enterprise compliance, slower warm-up |
Together AI | vLLM-based | Static batching | US-centralized | Limited | Shared GPU clusters; queue-based inference |
Each platform makes a different tradeoff between control and convenience; the real advantage lies in how much of your inference stack you own.
Skip the Global Queue by Owning Your Infra
Wondering how much latency and spend your shared endpoint is actually adding? Most teams lose more money to queuing delays than to GPU cost itself.
Run a quick workload benchmark with Pipeshift to see how much you’re overpaying — both in time and tokens. Get a clear readout of your latency profile and total cost per token before the next billing cycle hits.
